Docker – weiter gehts…
Vor einer Weile habe ich angefangen, über Docker und die Möglichkeiten nachzudenken… Nun ergab sich die Möglichkeit, zwei frische Server (identische Hardware) mit frischem Linux einzurichten. Zwei gleiche Server verlocken, ein redundantes System zu Bauen.
Überlegung zum Konzept
Baut man aber jetzt ein Corosync/Pacemaker Cluster als Hot-Standby auf dem Docker dann nur auf einem Knoten läuft? Dann hätte man durch Docker lediglich die Austauschbarkeit der Container gewonnen und der andere Server würde nur auf einen Ausfall laufen und bis dahin nur Strom verbrauchen. Ungenutzte Ressourcen – Das gefällt mir nicht!
Zeimlich schnell kommt man auf „Docker Swarm“. Damit wird aus mehreren Docker-Hosts eine Docker Plattform vielen Vorteilen. Die eingerichteten Container können z.B. über die gesammte Plattform verteilt laufen. Fällt ein Server weg, werden die dortigen Container auf den verbleibenden Servern neu gestartet. Neue Server ermöglichen eine Entlastung der bereits vorhandenen Server. Ich glaube von Hyperconverged Infrastructure oder Web-Scale ist man aber noch ein Stückchen entfernt.
Getting started…
Man installiert also auf beiden (oder mehreren) Servern Docker.
Ist dies erledigt, macht ein einfaches docker swarm init auf dem ersten Server und bekommt einen Befehl wie man weitere Knoten hinzufügen kann.
Obacht: Docker Swarm unsterscheidet zwischen Knoten des Typs Manager und Worker. Baut man ein kleines 1+1 Cluster, sollten beide Knoten Manager sein. Also muss man den zweiten Knoten auch unbedingt als solchen beim Swarm anmelden. Den Befehl dazu liefert der erste Knoten, in dem man docker swarm join-token manager ausführt.
Wenn man jedoch eine Horde Server zu einem Swarm machen will, nimmt man idealerweise 3 Server als Manager und den Rest als Worker. Man kann später auch noch definieren, ob Conainer in Services nur auf Worker oder auf allen Typen laufen sollen.
Erste Redundanzprobleme
Bei meinen übereifrigen Redundanztests (Abschalten eines Servers) musste ich feststellen, dass der Docker-Swarm nicht mehr funktionierte. Irgendwo bekam ich die Fehlermeldung, dass mehr als 50% der Worker-Instanzen verfügbar sein müssten, damit der Swarm funktioniert. Um hier auszuhelfen, habe ich Docker noch kurzerhand auf einem Raspberry Pi eingerichtet und ebenfalls als Worker hinzugefügt. Wenn mein Fileserver später mal aktualisiert ist, wird der als dritter Worker den Raspberry Pi ersetzen.
Der Swarm ist nun aber immerhin weiter existent wenn einer der beiden Server ausfällt.
GUI: Portainer
Um Docker leichter zu verwalten und nicht alles auf der Befehlszeile erledigen zu müssen gibt es diverse Management-Tools. Ich bin vorerst bei Portainer gelandet. Das Tool selbst läuft ebenfalls in einem Container:
docker run -d -p 9000:9000 --restart always --name portainer -v /opt/portainer-data:/data -v /var/run/docker.sock:/var/run/docker.sock portainer/portainer
Dieses Tool habe ich zunächst auf jedem Node als einzelnen Container laufen.
Wie schon im Artikel „Docker – eine Idee – eine Lösung“ erwähnt, sind Containerinhalte flüchtig. Nur das was im Image eines Containers steht, ist nach einem Container-Neustart wieder verfügbar. Um z.B. die eingerichteten Nutzerdaten von Portainer zu behalten, muss man das /data-Verzeichnis des Containers auf dem Host verbinden: -v /opt/portainer-data:/data Dann werden die Inhalte ausserhalb des Containers gespeichert und bleiben nach Beenden des Containers erhalten.
Neben der Möglichkeit die laufenden Container, Dienste etc. zu beobachten und im Detail zu untersuchen, gibt es auch eine Cluster-Visualisierung:
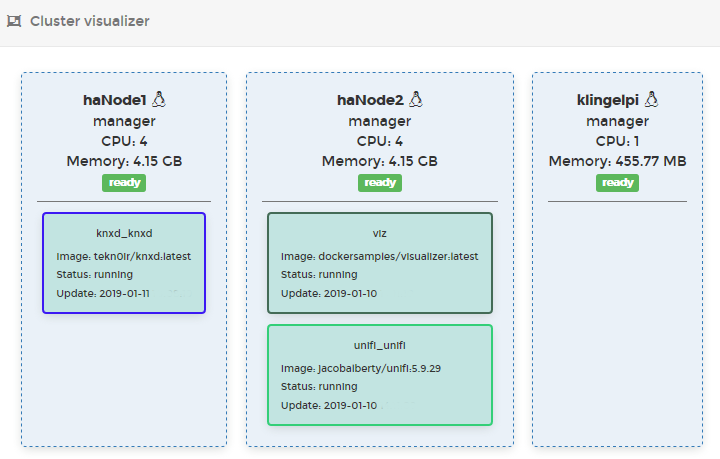 Der Container „viz“ im Bild ist eine unabhängige Visualisierung, die ich zu Testzwecken gestartet habe, um sie ggf. in eine Server-Monitoring-Statusseite zu integrieren:
Der Container „viz“ im Bild ist eine unabhängige Visualisierung, die ich zu Testzwecken gestartet habe, um sie ggf. in eine Server-Monitoring-Statusseite zu integrieren:
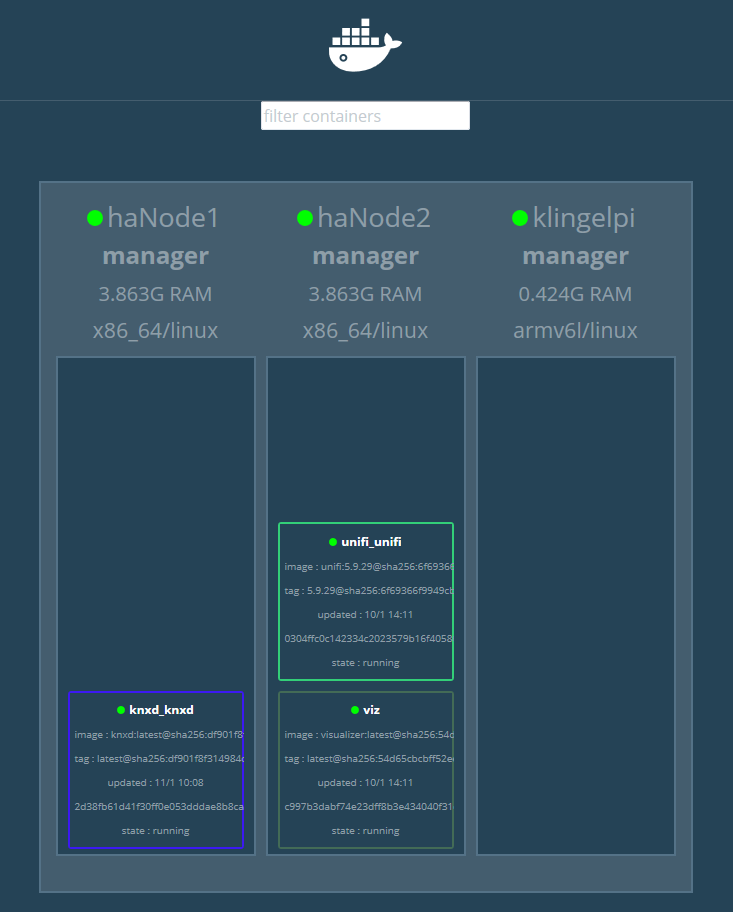
Weiter im Text: Docker als Swarm und Portainer laufen nun also.
Ach ja, damit alle Docker-Instanzen den Containern die benötigten Daten bereitstellen können, habe ich ein nfs-Share gemountet. Jede Anwendung bekommt ein Verzeichnis, welches dann als Bind-Volume in den Container gemapped wird. Hier habe ich noch das Problem, dass Container die ein chmod ausführen, abbrechen. Das hängt mit dem „Squashing“ zusammen, also der Sicherheitsfunktion, durch die ein root-user eines Hosts keinen root-Zugriff auf einen nfs-Mount erhält und entfernte uid zu „nobody“ übersetzt werden. Von Steffen habe ich den Tip mit der nfs-Option „no_root_squash“ auf dem nfs-Server bekommen. Leider konnte ich hier noch keinen Erfolg erzielen.
Um jetzt auch mal einen sinnvollen Dienst auf Docker ans Laufen zu bekommen, der im Zuge der ersten Tests auch mal ausfallen kann, habe ich mich entschieden den Unifi – WiFi – Controller als erstes im Swarm laufen zu lassen.
Der erste Versuch machte zwar das Web-Interface erreichbar, jedoch konnte kein Acces-Point discovered werden. Der Container lief in Docker über ein virtuelles Netzwerk, und alle Ports wurden willkürlich in das Host-Netzwerk übersetzt.
Im nächsten Versuch war dann alles besser:
docker run -d --init --restart=unless-stopped --name=unifi-controller --net=host --volume=/mnt/files/Docker/unifi:/var/lib/unifi -p 8080:8080/tcp -p 8081:8081/tcp -p 8443:8443/tcp -p 8843:8843/tcp -p 8880:8880/tcp -p 8883:8883/tcp -p 3478:3478/udp jacobalberty/unifi:latest
Der Container startet automatisch neu, wenn ihm was passiert. Alle benötigten Ports werden 1:1 zum Host übersetzt. Mit der Option –net=host wird der Container sogar direktes Mitglied des Netzes des Hosts.
Ein Container alleine ist auf den Docker-Host gebunden. Erst ein Service kann auf einem beliebigen anderen Hosts des Swarm neugestartet werden, oder sogar mit einer beliebigen Anzahl an Instanten über den Swarm verteilt gestartet werden.
Um einen Service zu definieren benötigt man Docker-Compose.
Docker-Compose ermöglicht es die Startoptionen von Containern in eine Datei zu legen, und auch noch weiterführend mehrere Container in Abhängigkeit zueinander zu starten. Solch einen Service-Stack kann man dann auf seinem Docker-Host ausführen, oder auf dem swarm deploy’n. Portainer bietet dazu einen Web-basierten Editor. Leider bekomme ich da immer Fehlermeldungen, die auf falsche Versionsnummern hinweisen. Führe ich docker-compose manuell mit der gleichen Datei auf der Kommandozeile aus, läuft alles wunderbar.
Meine Docker-Compose-Datei für den Unifi-Controller sieht wie folgt aus:
version: '3.7'
services:
unifi:
image: jacobalberty/unifi:5.9.29
restart: always
volumes:
- '/mnt/files/Docker/unifi_service:/var/lib/unifi'
- '/mnt/files/Docker/unifi_service/log:/var/log/unifi'
- '/mnt/files/Docker/unifi_service/run:/var/run/unifi'
ports:
- '3478:3478/udp'
- '8080:8080/tcp'
- '8081:8081/tcp'
- '8443:8443/tcp'
- '8880:8880/tcp'
- '8883:8883/tcp'
labels:
- 'unifi-controller'
Zu beachten ist, dass sich die Hierarchie der elemente durch die Einrückung (jede Stufe zwei Leerzeichen) ergibt!
Und ich starte den Servie mit: docker stack deploy unifi --compose-file=docker-compose.yml
Wobei man sich jedoch im Verzeichnis der Datei befinden muss. Der Verzeichnisname wird dann zum Namen des Stacks.
Loadbalancing..
Wenn ein Service nun auf dem swarm läuft, kann der Service über die definierten Ports über jede IP-Adresse der Swarm-Hosts angesprochen werden. Das ist einerseits gut. Im Falles des Ausfalls aber schlecht für die Clients, die auf den ausgefallenen Host eingestellt sind. Hier muss also vorgelagert eine Instanz in die Kommunikation eingefügt werden, die es ermöglicht, hochverfügbar über eine feste IP-Adresse angesprochen zu werden, und den Traffic auf die Docker Hosts verteilt. Auch wenn diese dann wieder alles zu einem Host schieben, wirkt das zunächst widersinnig. Wer weiß denn aber, ob mein Dienst irgendwann auf 3 Hosts läuft und eben für den ausfall, oder Umzug eines Containers soll ja alle aus Sicht der clients unverändert weiter laufen.
Daraus ergenen sich nun für mich weitere ToDos:
- Einrichten eines High-Availability Clusters (Corosync/Pacemaker)
- Einrichten eines Loadbalancers, der mehr kann als nur http-Traffic
- Der Loadbalancer sollte idealerweise auch in Docker (nicht zwingend im Swarm) laufen und sich eine IP-Adresse schnappen, die von Pacemaker je nach Clusterzustand auf einem Host aktiviert wird (ähnl. VRRP).
Neue Erkenntnis…
Beim Einrichten von Corosync/Pacemaker ist mir die Idee gekommen, dass die Docker Container im Swarm über die IP-Adressen der Hosts erreichbar sind. Da die von Pacemaker gesteuerte virteulle-IP im Betriebssystem genauso zu finden ist, wie die herkömmlich konfigurierten Adressen, müsste es doch auch gehen direkt über die Adresse einen Dienst auf zu rufen. Tatsächlich! Der Unifi-Controller ist direkt über die Cluster-IP zu erreichen. Klasse – den komplizierten Loadbalancer, der für jeden weiteren Dienst angepasst werden müsste, kann ich mir sparen! Jeder der schonmal nen f5 Big-IP in den Fingern hatte weiß, weiß was ich meine….
Die Einrichtung von Corosync/Pacemaker werde in einem gesondertem Beitrag beschreiben.